新闻网讯 12月11日,人工智能与自动化学院张海涛教授、卢仁智副教授与机械学院丁汉院士联合团队在Nature Communications发表题为“具身强化学习智能体的奖励函数发现(Discovery of the Reward Function for Embodied Reinforcement Learning Agents)”的研究论文。论文提出了一种具身智能体自主发现最优奖励函数的框架,实现了智能体策略与奖励函数的协同进化。卢仁智副教授为第一作者,张海涛教授、西班牙纳瓦拉大学丁月民教授为论文通讯作者,丁汉院士为论文共同作者,人工智能与自动化学院为论文第一完成单位。

作为人工智能基础研究的核心组成部分之一,强化学习通过智能体与环境的交互,以最大化累积奖励为目标进行决策优化,该过程因其模拟人类通过试错和经验学习的行为而被广泛认为是接近人类智能的决策范式。奖励最大化是生物体生存与进化的核心机制,也是驱动智能体感知、模仿与学习等复杂能力的重要准则。然而,奖励函数的设计质量直接决定了强化学习智能体的学习效率与最终性能,其构建方法仍是当前研究中的关键瓶颈。传统奖励函数的设计高度依赖复杂且繁琐的人工调试,不仅耗时费力,还容易引发“奖励黑客”现象。同时,现有奖励函数设计方法需要获取高质量的专家演示或人类反馈,应用门槛与成本较高,并且在复杂动态的任务中往往难以提供有效引导,限制了智能体的泛化能力与学习上限。因此,如何实现奖励函数的自动设计与自主优化,已成为强化学习研究中一项亟待解决的重要挑战。
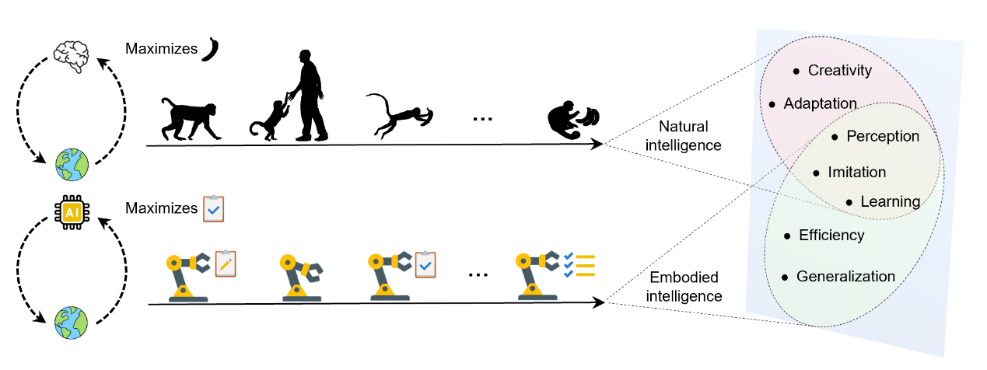
图1自然智能与具身智能中的奖励最大化机制
该研究从自然界生物进化角度入手分析了自然智能与具身智能的奖励最大化演进范式,并基于遗憾最小化思想提出了一种最优奖励函数自主发现框架。该框架通过双层优化机制,在具身智能体策略进化的过程中自主发现最优奖励函数,并提升具身智能体的学习性能和加快策略优化进程。与传统手工设计和基于领域知识学习的奖励函数相比,该方法最大可将算法决策性能提升130%;同时在达到相同决策水平情况下,该方法可将迭代次数降低50%,有力增强了智能体的自主学习和适应能力。在智能无人系统自主作业、机器人控制、能源管理等多个实际Benchmark任务中,所发现的奖励函数能准确识别关键状态并引导智能体完成复杂决策,其性能显著超越现有奖励设计方法,具备广泛的应用潜力。
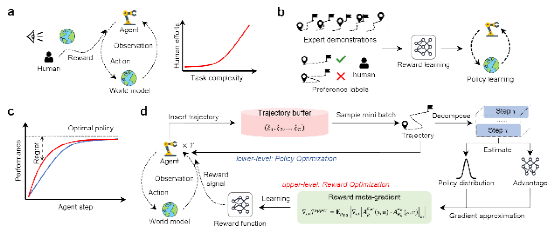
图2 (a)奖励函数手工设计范式(b)基于领域知识学习奖励函数范式(c)遗憾最小化思想(d)所提出的最优奖励函数自主发现范式
该基础研究解决了强化学习研究中长期存在的奖励函数手动构建复杂、泛化能力不足的核心问题,并揭示了奖励函数驱动强化学习智能体决策的内在机理。该研究提出的最优奖励函数自主发现框架不仅为强化学习奖励函数设计提供了全新的自动化范式,也为实现通用人工智能与具身智能系统奠定了重要基础。该成果将大幅提高具身智能体在开放世界任务中的决策可靠性与自适应能力,从而助力提升具身智能体的整体智能化水平,并有望在机器人、智能制造等多元现实场景中展现应用价值。
该研究得到了国家自然科学基金科学中心项目、国家自然科学基金杰出青年基金项目、联合基金重点项目、国家科技创新2030重大项目等资助。作者还包括人工智能与自动化学院伍冬睿教授、苏厚胜教授、硕士生邵宗贺、香港城市大学王钧教授、加拿大维多利亚大学施阳教授、美国纽约大学姜钟平教授、香港科技大学张福民教授、东北大学杨涛教授和武汉纺织大学陈蕊娟讲师。
论文链接:https://doi.org/10.1038/s41467-025-66009-y




